01. 容器监控痛点
近年来,Kubernetes 作为许多公司云原生改造的首选容器编排平台,越来越多的开发和运维工作都围绕 Kubernetes 展开,保证 Kubernetes 的稳定性和可用性是基本需求,而其中的核心是如何有效地监控 Kubernetes 集群,确保整个集群的高可观测性容器监控常常会有以下痛点:
- 动态环境与复杂架构
容器化环境通常是高度动态和分布式的,这意味着容器生命周期短且频繁变化,同时应用由多个微服务组件构成,分布在多个节点上。这种动态性和复杂性要求监控工具能够快速适应环境变化,并有效地追踪跨多个服务和节点的问题。
- 数据量大与性能开销
高频率的数据收集和大量的日志、指标数据会迅速增长,给存储和处理带来挑战。另外,监控系统本身引入的性能开销也需要谨慎管理,以免影响应用程序的正常运行。
- 多层次监控需求
容器监控需要覆盖多个层次,包括底层基础设施、容器运行时、容器编排平台,以及应用层面的性能指标和日志数据。
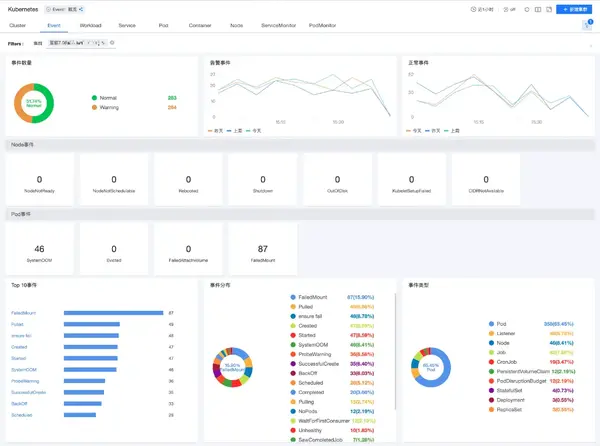
02. 场景介绍
容器监控,泛指在容器场景下,对容器环境的指标、事件等进行上报。目前市面上的容器管理平台,基本被Kubernetes所统一,本文将核心围绕Kubernetes的场景及特性,介绍betway必威蓝鲸监控中心(下称“监控中心”)是如何实现容器监控的。
不同于常见的主机监控、组件监控等成就,容器监控具备以下几个鲜明的监控特性:
- 监控目标是动态的,无法通过传统的方式对指定目标IP、目标端口进行监控。
- 由于容器的频繁销毁与创建,监控目标展现出极高的动态性,缺乏有效的监控手段将直接导致难以追溯。
- 无需关注容器具体运行在哪台机器上。
- 容器的数量多,上报的指标量级多。
围绕着上面的特性,容器监控的诉求主要分为以下几点:
1)集群本身的运行状态监控,监控的目的是随时关注容量、及时发现异常,让集群的运维者能够快速修复集群问题。
- 对Kubernetes集群状态的监控,如Master集群的etcd,Kube-api、Kube-scheduler、Kube-proxy、Kubelet等核心服务的监控。
- 对Node节点状态的监控,如CPU、内存、网卡等监控。
- 对资源的统计需求,如Cluster、NameSpace、 Node、Pod数量的统计。
- 对Workload、Service、Pod、Container运行指标和状态监控。
2)Kubernetes事件监控记录了组件的某个时间的动作,用于展示集群内发生的情况,当集群内的资源状态发生变化时产生新的event,对容器事件的收集、监控,避免集群或节点可用性产生的影响。
- 容器事件:如容器启停状态、拉取/创建/启动容器失败等;
- 节点事件:如节点添加/删除、节点状态变化、节点可用性等;
- Pod事件:如创建Pod成功/失败、删除pod成功/失败等.
3)自定义指标的监控:
- 对于运行在容器中的服务而言,仅仅依赖运行环境的指标正常性来评估服务状态是不足够的。因为即便运行环境(如CPU、内存等)指标表现正常,因此需要上报服务本身的指标。
- 服务的指标,如接口的成功、失败、饱和度、错误率等,通常这类指标对应用开发来说,更具有实际参考价值,更能够对业务有帮助。
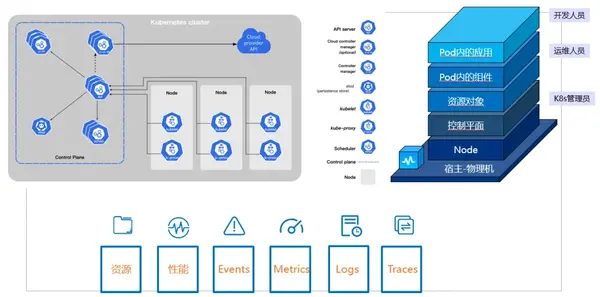
03. 产品方案
对于K8s的监控,其实已经有一套原生的Prometheus方案,方案本身采集的指标相对完善,但是核心问题是对集群性能有较大的占用,且整体部署方式相对独立,采集的指标无法结合其他监控产品进行有效的消费。
为了让大家统一集中管理监控,将容器监控与主机监控,业务监控等融为一体,监控中心推出了容器场景的监控能力。可以解决以下问题:
- 避免Prometheus服务在高负载情况下OOM,查询无响应,可用性不高问题。
- 无需每个Kubernetes集群独立部署Prometheus。
- 解决容器监控和业务监控割裂使用的问题,集中式查看监控、告警,让监控数据在统一的地方消费使用,无需同时维护多套监控系统。
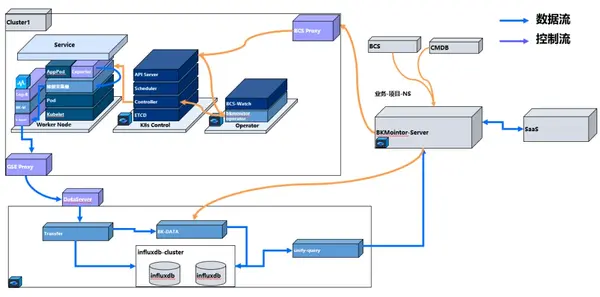
得益于监控中心化的存储能力,Bkmonitor-operator 较 Prometheus-operator 方案,对集群内资源消耗更低。
04. 效果展示
1)容器多指标计算检测
容器监控的指标数量庞杂,许多指标均需经过二次计算,甚至无法通过常规的配置方式配置检测策略。对此,监控中心同步提供以下两个检测能力:
① 衍生指标管理
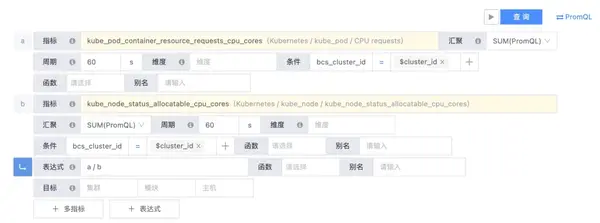
支持衍生指标能力,允许用户通过指标计算自定义衍生指标。要知道,在容器内,许多上层资源指标都是由下层指标汇聚计算而来(比如Cluster的性能指标,其实是Pod性能指标汇聚计算获得),通过衍生指标功能,用户可以预定义上层汇聚指标,并在策略配置,可视化展示时直接消费,而不需要每次都重复配置计算规则。
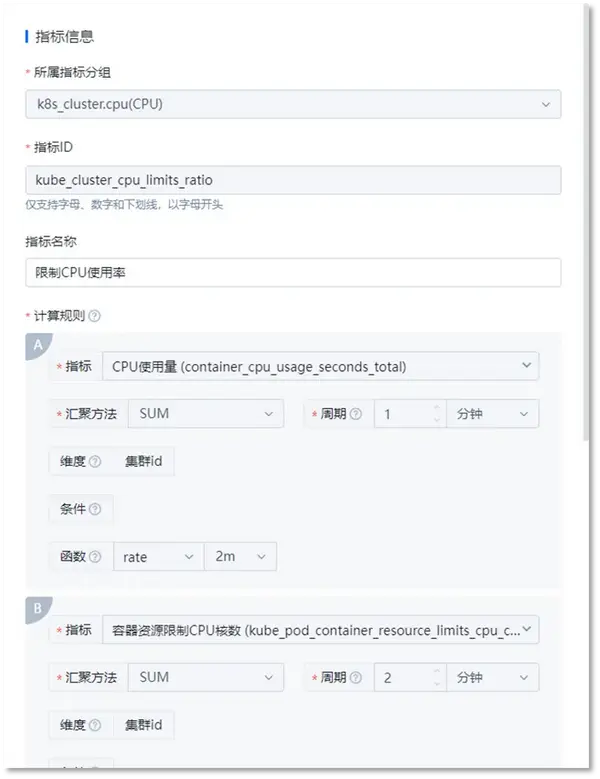
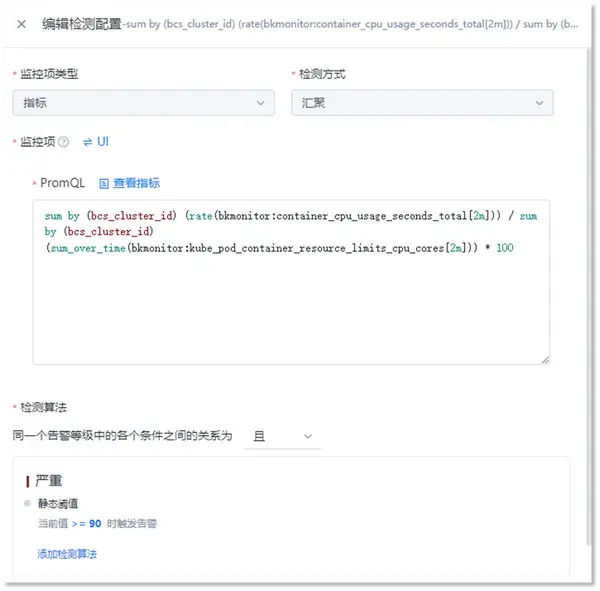
② 兼容PromQL表达式
完全兼容PromQL检测预计,实现更多样化的检测逻辑,应对容器监控下复杂的监控检测需求。
③ 容器资源监控
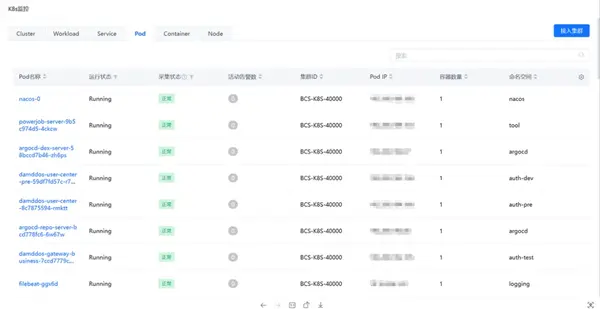
监控中心支持对容器内各类资源对象进行发现,并采集相关性能指标,包括以下对象:
- Cluster
- Workload (DaemonSet、Deployment、StatefulSet、Job、CrontJob、GameStatefulSet、GameDeployment)
- Pod
- Container
- Node
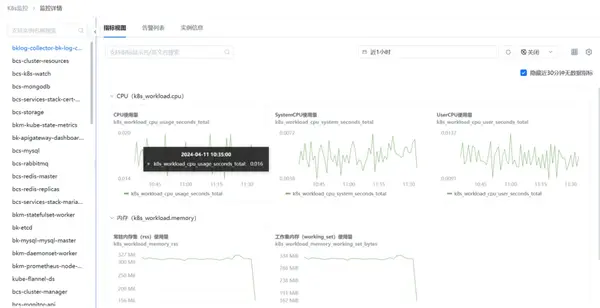
支持按照容器实例查看对应的实时指标视图、告警数据以及实例本身的信息。
④ 容器组件服务监控
对于容器上部署的组件服务,监控中心支持通过多种方式进行监控:
- 支持serviceMonitor(主推)和PodMonitor;
- sidecar方式( 以sidecar模式部署exporter抓取器暴露出metrics,结合serviceMonitor进行采集);
- 中心远程统一采集 (组件本身暴露了metrics,结合serviceMonitor进行采集)。
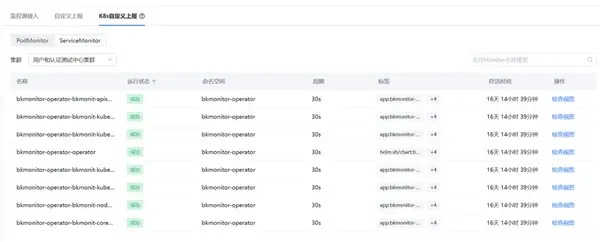
支持检索查看上报后的指标实时数据。
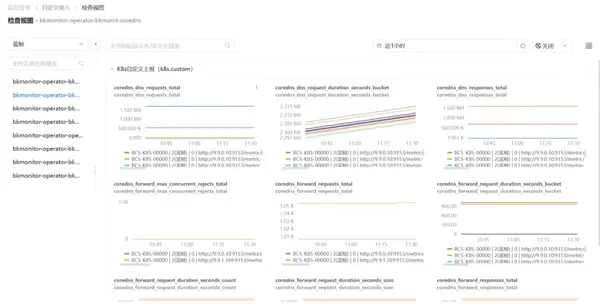
⑤ 容器日志监控
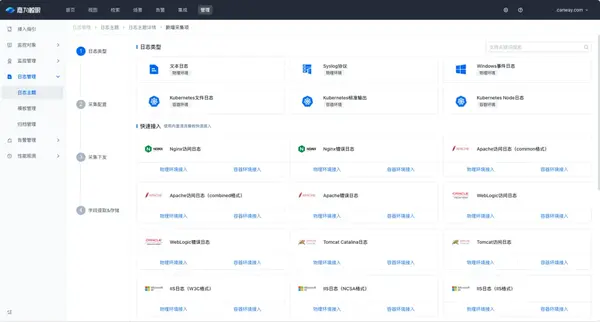
对于容器上的日志,监控中心支持采集以下类型的日志:
- 支持采集在容器上运行的文件日志,即应用/服务产生的文本日志,例如Nginx日志、业务日志等;
- 支持采集K8s Node日志;
- 支持Kubernetes的标准输出,即Pod容器的标准输出,包含标准输出信息(stdout)和标准出错信息(stderr),输出路径为容器的/dev/termination-log文件。
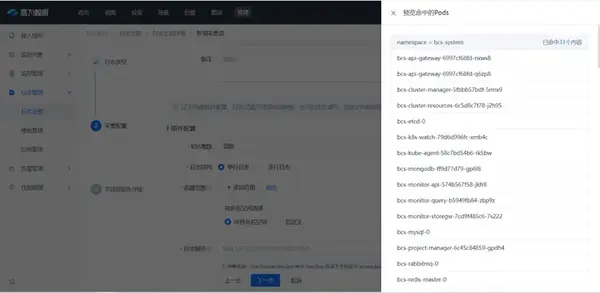
配置容器采集时可根据需要选择指定的Pods。
05. 最佳实践
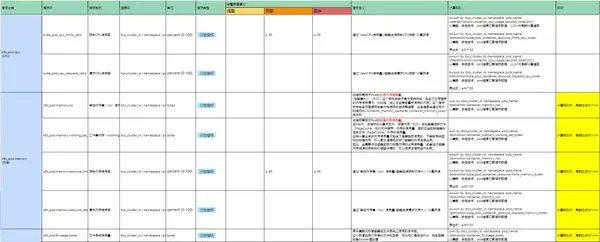
容器监控场景由于自身的复杂性,即使在技术上我们实现了对目标的全量监控、采集,但是如何配置有效的告警依然是用户实施容器监控的一大难点。
为了帮助在容器监控场景下经验不深的用户,监控中心不仅内置了默认的容器监控策略、容器仪表盘,同时还提供了详尽的指标说明文档和最佳实践配置指引,帮助用户全面了解容器监控数据。
相关文章推荐
DevOps系列:CICD流程建设之持续测试实践指南

 2024-10-16
2024-10-16
查看详细


betway必威蓝鲸配置管理中心重磅发布,数据运维全面升级!
2024-10-16
查看详细
betway必威蓝鲸 WeOps V4.15上新 | 增强阿里云资管和监控能力
2024-09-11
查看详细
【新品发布】betway必威蓝鲸WeOps运维平台一体机全新发布:高性价比、强大稳定、即插即用的企业级IT运维设备
2024-09-11
查看详细
一文掌握DevOps落地的终极实践,8大关键路径揭秘!
2024-09-10
查看详细
DevOps 组织的建设密码:人才胜任力模型全解析
2024-09-10
查看详细







