近年来,可观测性建设已经成为企业数字化转型的高热话题,但大多数企业在实践落地过程中往往会发现,以往的建设模式并不能够在企业中发挥良好的作用,单纯的引入产品或工具已经没有办法达到建设需求。本期我们邀请到betway必威蓝鲸运维产品负责人宋蕴真,从战略管理,到组织度量,最后再到工具应用层面对可观测落地实践进行深度剖析,自上而下对可观测落地建设进行梳理,带您一步步深入探索可观测性的落地实践。
01. 战略目标:服务于业务
数字化转型是一个长期过程,早期企业IT运维主要还是面向物理设备,而随着技术架构的不断发展,运维对象逐渐向虚拟化、云化趋势发展,软件架构逐渐向SOA、云原生等架构转变。业务的线上化趋势下,传统IT运维往往无法及时感知和处理问题,企业运维处于黑盒化状态,在此背景下,运维管理体系需要向自动化、智能化转型,以服务于快速发展的企业业务。
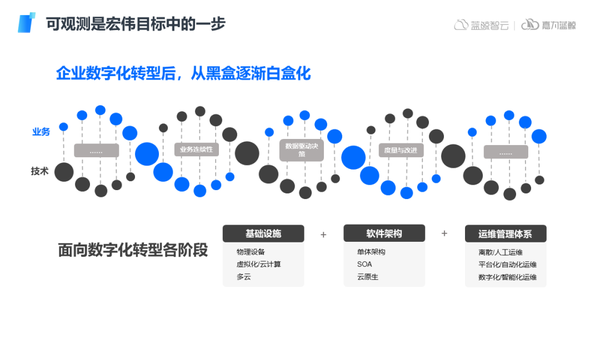
在数字化转型过程中,运维的核心目标就是保障业务的连续性,IT运维整体的转型战略目标也需要始终服务于业务,在不同的建设阶段通过不同方法和手段,快速的发现问题、解决问题可观测是IT数字化转型宏伟目标的其中一步,通过可观测体系的建设,不断提炼运维数据价值,帮助和驱动业务部门决策,并在这个过程中对IT组织进行持续的度量和改进,最终更好的推进企业数字化转型宏伟目标的实现。
1)可观测建设的核心目标与挑战
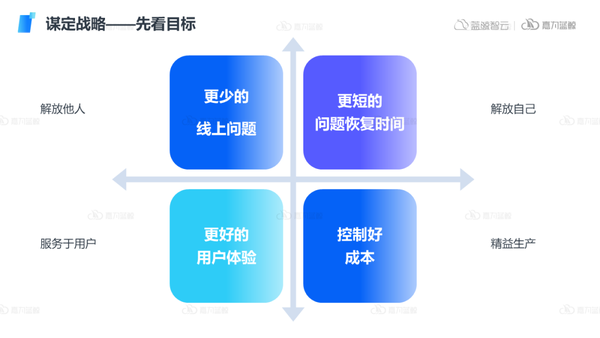
可观测的建设是服务于业务的,首先需要细分并明确可观测建设的核心目标。
- 更少的线上问题:当业务出现问题时,往往不是独立存在的,可能会引起上下游的组织、业务、人员出现更多的问题,导致组织的效率低下或运维成本增加,而通过可观测建设,减少问题的出现,能够解放他人,让更多的人员能够投入到其他工作中,实现降本增效。
- 更短的问题恢复时间:IT业务几乎无法避免问题的出现,SLO也不可能是100%,如何提早发现问题,更快的解决问题,或者采取自动化的方式处理重复工作,从而将运维人员自己解放出来,投入到更加价值的工作中,也是可观测的核心目标之一。
- 更好的用户体验:业务最终是面向用户的,通过可观测的建设,提高系统稳定性和可用性,保障良好的用户体验,真正服务于用户。
- 控制好成本:生产成本的控制往往也离不开可观测,企业的降本增效需要IT能够快速感知资源状态,从而合理度量和分配IT资源,实现精益生产。
与此同时,云原生技术下的IT系统日益复杂,历史系统、工具难以一时替换,而国产替代、自主可控又提出了新的要求,实现目标的挑战也越来越大:
- 海量:面向大集群、多中心的集中观测,技术挑战、系统可用性挑战高。
- 历史包袱、烟囱林立:监控工具多,相互独立,数据分散,管理复杂,烟囱林立。
- 工具联动弱:运维工具难以互联互通,监控处置慢,人员协同差,运维效率低,告警模式单一,无故障根源分析能力。
- 分布式系统日益复杂:运维对象日趋复杂,IT技术架构变化大,IT对象井喷式增长。
- 兼顾历史与未来:既要能够纳管古老的IT对象,又要能够纳管先进的云原生、信创对象。
- 运维对业务的感知不足:运维侧往往被动响应问题,需要从问题导向逐渐向主动地规划导向演进。

02. 战略拆分:问题处理的生命周期
确立总体服务与业务的战略目标后,需要对目标进行一步步的拆分。通常情况下可观测应用场景主要集中在处理IT运维问题上,而运维人员在工作中真正遇到故障时主要包括故障的发现、定位和恢复过程,但除了这些故障处理工作之外,故障提前预防以及故障事后复盘根治也是故障全生命周期中的重要环节。
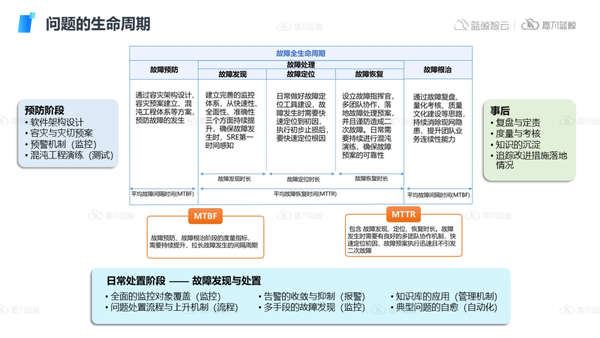
在不同的生命周期阶段可观测性也会有不同的关注点,我们需要把各个阶段的目标进行细化,最终实现贯穿故障全生命周期的闭环处理,从而减少故障的发生频率和故障恢复时间,提高运维整体效能。
1)预防阶段
预防阶段主要关注以下几个方面,来降低故障发生的频率,做好预防阶段的规划也是提高SLA的最根本的手段,通常这类规划不会单独由运维来执行,而是需要整体团队协同配合,共同达成的目标。
2)软件架构设计:
● 技术选型:选择相对主流、稳定的基础组件来构建生产系统。
● 易维护性:建立自身产品的可观测,工具支持快速告警,支持干预,易恢复。
● 高可用设计:冗余设计与建立容灾机制。
● 事务性:处理好分布式事务,保障数据一致性。
● 可扩展:对能力进行抽象与配置驱动,实现扩展性。
3)容灾与灾切:
● 容灾:通过采取预防性措施,在系统发生故障时能够顺利恢复,从而避免系统瘫痪。常见的容灾措施包括备份和恢复、冗余、负载平衡等
● 灾切:在系统发生故障时,快速的切换到备用系统,避免业务中断。通常需要在容灾措施的基础上进行,需要对备用系统进行定期测试和维护
4)预警机制:
● 定指标:利用观测指标作为预警指标,可以是资源使用率或特定日志
● 设阈值:合理设置触发阈值,考虑好检测周期与指标周期的匹配
● 建流程:为不同级别的事件设计相应的处置流程,对于跨部门问题处理要建设问题支持工单流程。
5)混沌工程(测试):
● 目的:通过测试确保软件质量,通过混沌工程提高软件质量
● 方法:混沌工程通过模拟现实世界的混沌环境,来测试软件的可靠性和可用性,而测试则是通过执行特定的测试用例,来检验软件是否能够满足需求。
● 落地:大多数企业的业务规模下,我们需要做好测试工作,保障业务正常运转。只有在一些互联网企业,针对大型分布式系统时可能才会涉及到混沌工程的建设。

6)问题处置阶段
在日常处置问题的阶段,运维人员主要关注两个核心指标:MTBF,MTTR。
MTBF:故障预防、故障根治阶段的度量指标,需要持续提升,拉长故障发生的间隔周期。
MTTR:包含故障发现、定位、恢复时长。故障发生时需要有良好的多团队协作机制,快速定位初因,故障预案执行迅速且不引发二次故障。
在这一阶段运维人员可以从监控、告警、流程、自动化以及管理机制等多个方面着手处理,其核心目标就是将平均故障恢复时间(MTTR)尽可能降低,保障业务的连续性:
- 发现:通过监控,日志,链路等工具及时发现问题。
- 定位:通常会有大量告警产生,需要对告警进行抑制、降噪,对问题进行降维,对部分问题还需要与其他团队协同定位,同时对于一些关键问题需要建立及时上升的机制。
- 根因:定位到问题以后,基于时间、关系进行更深一步降噪,对各类指标进行明细排查,同时通过日志、链路等工具的联动确认根因。
- 恢复:恢复阶段除了手动的操作以外,类似应用发布场景下,可以将发布操作,发布回滚等一些可复用场景进行自动化能力的积攒,以提高故障恢复效率。
- 记录:通过问题本身的记录,协作卡点的记录,对问题做一些简单的闭环,以支撑后续在复盘阶段更加深入的分析故障根治。

7)事后根治与复盘
故障的根治并不代表能够彻底消除故障,而是通过事后的复盘和一些处理手段的总结,能够尽量减少同类故障的发生,同时在过程中通过对人员的管理和考核手段,做好良好的文化建设,避免“追责”、“甩锅”、“自黑”、“卖惨”等不良文化,进行团队可持续性优化和改进。
- 在实际生产中,可以采取以下措施:
- 如实记录,留下经验记录。能够为团队提供相关场景和案例进行学习和参考。
- 对用户(客户)有交代,能够给用户营造出团队的专业感。
- 对续规避措施的持续跟进和对改进效果的检查也需要依赖故障详细信息。
- 通过事后复盘,提炼出易用性,易维护性,健壮性等方面的潜在需求。

03. 组织管理:可度量考核
可观测建设并不只是软件或者工具的建设,在实际落地过程中,最终面向工具的还是“人”。除了工具的建设,可观测的组织文化建设也是必不可少的。而是否对组织进行了合理规划、组织之间是否能够高效协同配合,是否建立了可度量的考核体系,对提升企业整体运维水平也起着十分关键的作用。
1)组织划分
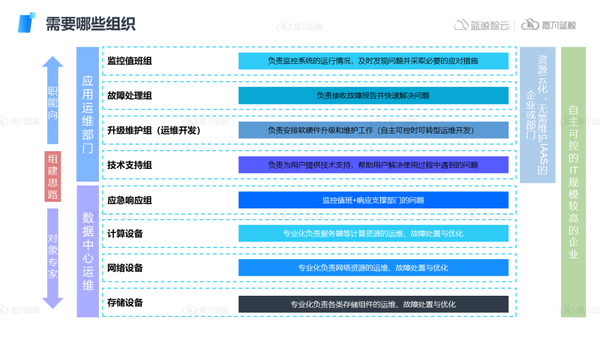
首先需要明确在故障处理全生命周期中,需要哪些组织的参与,通常我们的组建思路会分为上下两部分:
2)向上
应用运维部门,这类组织面向的运维对象是多方面的,并不会专精于某一个对象之中,通常会偏向职能层面。
- 监控值班组:负责监控系统的运行情况,及时发现问题并采取必要的应对措施
- 故障处理组:负责接收故障报告并快速解决问题
- 升级维护组(运维开发):负责安排软硬件升级和维护工作(自主可控时可转型运维开发)
- 技术支持组:负责为用户提供技术支持,帮助用户解决使用过程中遇到的问题
3)向下
数据中心运维。更多组建的是对象专家团队,分别对各类资源去设计组织,确保团队的专业性,针对相应问题能够有效提供解决方法。
- 应急响应组:监控值班+响应支撑部门的问题
- 计算设备:专业化负责服务器等计算资源的运维、故障处置与优化
- 网络设备:存储专业化负责网络资源的运维、故障处置与优化
- 存储设备:专业化负责各类存储组件的运维、故障处置与优化
4)组织协同配合
组织间的协同与配合在许多企业中是较为棘手的,部分企业并没有针对团队协同做相关的建设,通常是靠人际关系来推动问题的解决,而建立良好的协作机制与完善的问题处理流程能够大大提升企业组织效率,并实现可推广的组织文化。
这里我们以组织间协作的常见流程ITR(issue to resolved)为例:
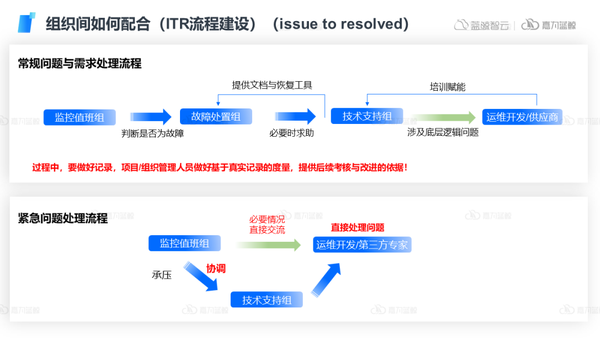
在常规问题处理过程中,要做好信息化的ITR流程记录,同时做好基于真实记录的度量,为后续的考核与改进提供有力的依据。
在紧急问题处理下,做好问题的上升,快速将无法解决的反馈到更加专业的团队中,使得问题能够得到更有效的处置,从而更快速的完成问题闭环。
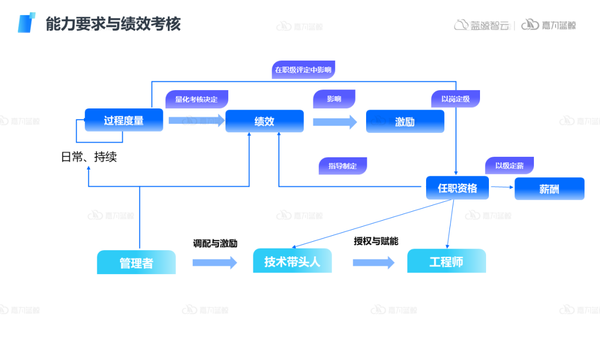
5)能力要求与绩效考核
通常绩效考核也是企业IT组织较为头痛的问题。在绩效考核上,核心是要持续不断的做好日常工作的过程度量,从而才能够量化考核决定绩效指标,最终影响提现在激励上。
同时整个过程的度量可以用于人员的职级评定的重要指标依据,管理者需要做好资源的调配与激励规划,同时在组织中要推动技术带头人不断赋能工程师,团队内部互相扶持进步,实现整体团队的前进,从而形成良好的组织管理闭环。
04. 工具应用——匹配战略战术
1)可观测工具:
在故障发现和恢复的第一阶段,仍然是监控告警等观测工具,对原始三大支柱数据:日志数据、指标数据、链路数据进行采集分析处理,基于这些基础数据,做好监控告警策略的配置,实现事件的监控与发现。
2)自动化工具:
在故障处理的中期阶段,主要是自动化的工具体系,在这一过程中积累一些自动化能力,实现简单故障的自愈,复杂问题可以同时结合人为判断和以往经验沉淀进行处理,建立故障处置能力。一般来说自动化工具体系最好是与监控、告警等观测工具相互结合使用,更高效的完成故障处理。

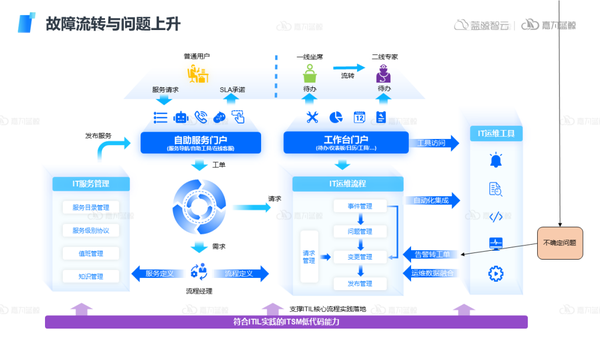
3)流程流转工具:
对于一些不确定的、无法解决的复杂的问题,难以在IT组织内完成闭环的,可以通过流程体系的建设,做好故障的流转与问题的上升。可观测工具、自动化工具与流程体系的相互融合以达到故障的全生命周期管理。
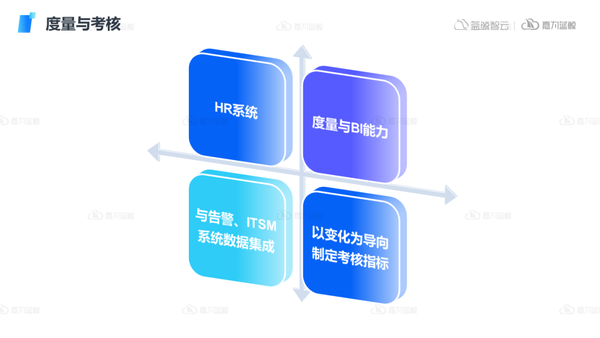
4)组织管理:
最后是结合上文对组织度量和考核的建设,对涉及到的HR系统、度量与BI能力、ITSM等进行相应的配套优化,以度量数据为基础,以变化为导向制定考核指标,从而实现有效的组织管理。
可观测的落地是一个庞大的工程,本期我们仅仅只从部分维度分享了关于战略管理到工具落地的相关经验,对于监控告警指标设计、日志管理、应用体验优化等更加细分的内容,我们将在可观测系列直播中进行更加深入的分享,如果您感兴趣或有相应建设需求,欢迎联系我们!
相关文章推荐
DevOps系列:CICD流程建设之持续测试实践指南

 2024-10-16
2024-10-16
查看详细


betway必威蓝鲸配置管理中心重磅发布,数据运维全面升级!
2024-10-16
查看详细
betway必威蓝鲸 WeOps V4.15上新 | 增强阿里云资管和监控能力
2024-09-11
查看详细
【新品发布】betway必威蓝鲸WeOps运维平台一体机全新发布:高性价比、强大稳定、即插即用的企业级IT运维设备
2024-09-11
查看详细
一文掌握DevOps落地的终极实践,8大关键路径揭秘!
2024-09-10
查看详细
DevOps 组织的建设密码:人才胜任力模型全解析
2024-09-10
查看详细







